Zhejiang University和上海AI实验室已发行创建 - 姆姆班克,专门设计的基准在现实世界中评估多模式的创造力。该工具揭示了有关当今最先进的创意能力的令人惊讶的见解AI模型,包括发现GPT-4.5的创造力落后于GPT-4O在许多情况下。
超越传统的AI评估
虽然GPT-4.5受到广泛赞扬由于在日常问答和各种创造性任务中令人印象深刻的上下文连贯性,研究人员确定了一个关键问题:在哪里到底是创造力天花板“ 的多模式大语言模型(MLLM)?
挑战是在复杂方案中衡量创造力。现有基准难以量化AI模型是否产生真正的创造性见解,许多测试场景过于简单,无法反映这些模型在现实世界中创造性思维情况下的表现。
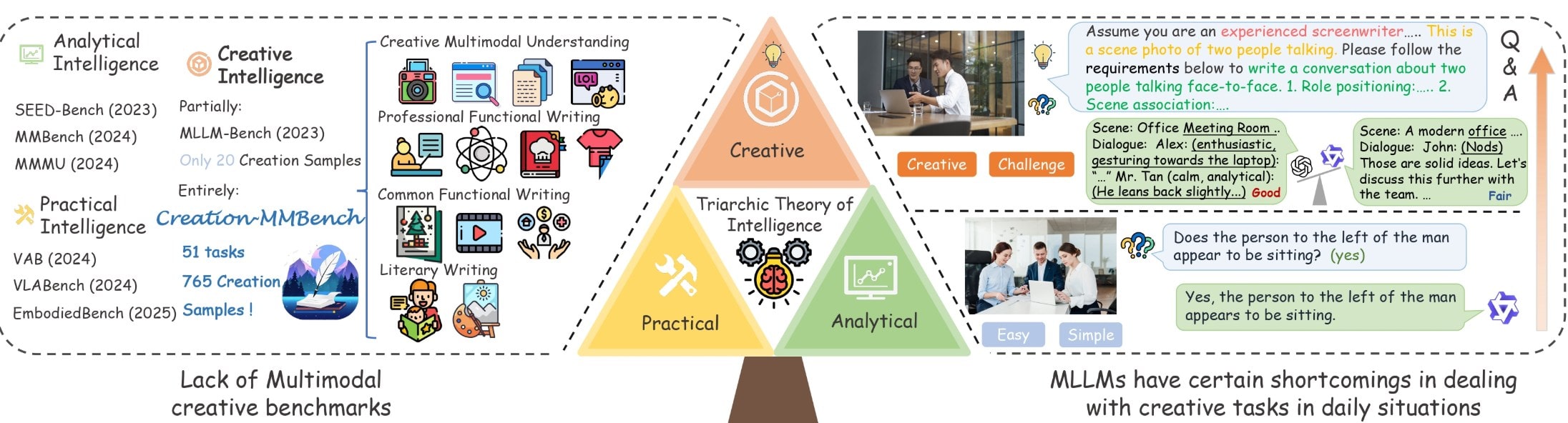
Creation-Mmbench通过全面评估“视觉创意智能在四个主要任务类别中,51个细粒度的任务,和765具有挑战性的测试用例。
为什么视觉创意智能很重要
创意情报传统上是最具挑战性的方面人工智能评估和发展。与清晰正确或错误答案的分析任务不同,创造力涉及在各种环境中生成新颖而适当的解决方案。
当前的MLLM基准类似mmbench和mmwanness,主要关注分析或实践任务,同时忽略与多模式AI相互作用中常见的创造性挑战。 Creation-Mmbench通过具有各种内容以及单像图像和多图像问题的复杂场景来与众不同。
例如,基准测试挑战模型:
- 引人入胜的博物馆展览评论
- 根据人们的照片写情感,故事驱动的论文
- 作为米其林厨师解释食物照片,创建细微的烹饪指导
这些任务需要同时掌握视觉内容理解,上下文适应和创造性的文本生成 - 现有基准的能力很少经过全面评估。
Creation-Mmbench的严格评估框架

基准分为四个主要任务类别:
- 文学创造:通过诗歌,对话,故事和叙事结构评估艺术表达
- 日常功能写作:测试社交媒体,公共计划,电子邮件和现实生活问题的实用写作
- 专业功能写作:评估室内设计,课程计划和景观描述的专业写作
- 多模式的理解和创造:通过文档分析和摄影赞赏检查视觉文本集成
设定创建的原因是它的复杂性。它结合了近30个类别的数千个跨域图像,每个任务最多支持9个图像输入。测试提示是全面的,通常超过500个单词,以提供丰富的创意背景。
双重评估系统量化创意质量
为了客观地量化创意质量,团队实施了双重评估方法:
- 视觉事实得分(VFS):确保模型准确地读取图像细节而不制造信息
- 报酬:评估模型的创造力和表现能力与视觉内容结合
评估过程使用GPT-4O作为评判模型,考虑了评估标准,屏幕内容和模型响应,以提供模型答复和参考答案之间的相对偏好评分。
为了验证可靠性,人类志愿者手动评估了13%的样本,证实GPT-4O表现出与人类偏好的强烈一致性。
基准结果:封闭与开源模型
研究团队使用VLMEVALKIT工具链评估了20多个主流MLLM,包括GPT-4O,Gemini Series,Claude 3.5以及Qwen2.5-VL和Internvl等开源模型。
关键发现:
- 双子座2.0-Pro在多模式创意写作中的表现优于GPT-4O,尤其是在日常功能写作任务中
- GPT-4.5表现出比两者都弱的总体表现双子座-Pro和GPT-4O,尽管它在多模式内容理解和创建方面非常出色
- 开源模型QWEN2.5-VL-72B和internvl2.5-78b-mpo具有与封闭式模型相当的创意功能,但仍显示出性能差距
特定于类别的见解:
- 专业功能写作事实证明,由于对专业知识和深厚的视觉内容理解的需求很高,因此被证明是最具挑战性的
- 在与日常社交生活相关的日常任务中,情况和视觉内容更加简单。
- 大多数模型在多模式理解和创建任务上都获得了高视觉事实分数,但基于视觉内容而苦苦挣扎
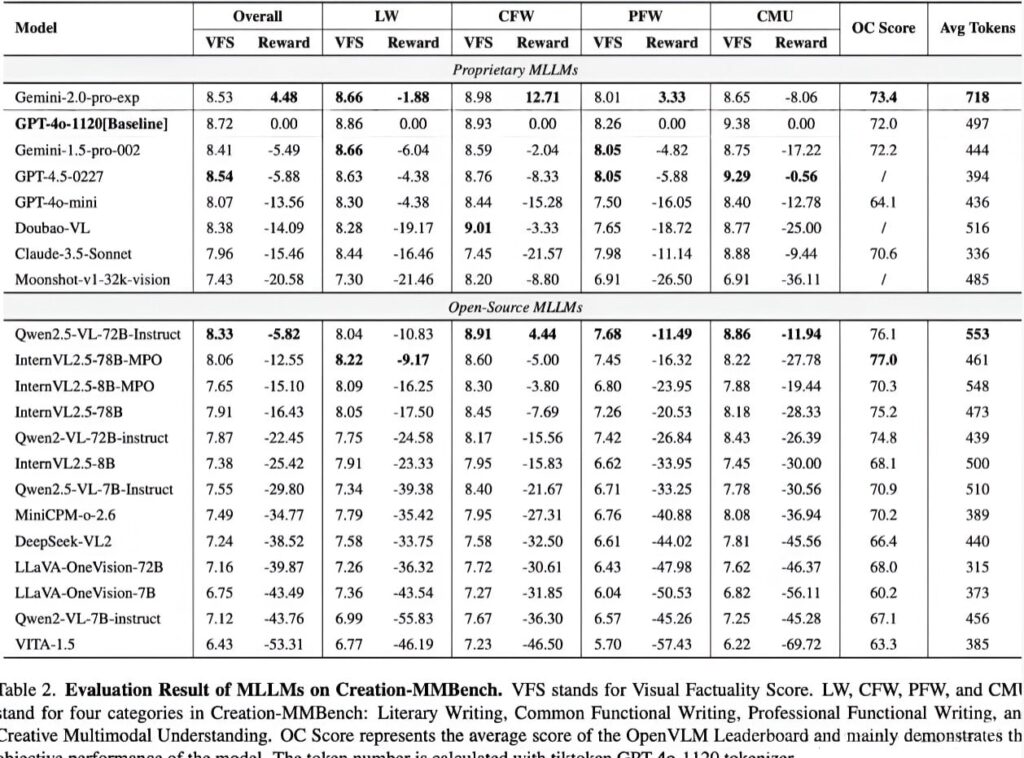
专业功能写作证明了任务类别中最具挑战性的,因为它对专业知识和深入的视觉理解的要求。相比之下,由于与常见社交场景相似,日常功能写作任务的表现更高。

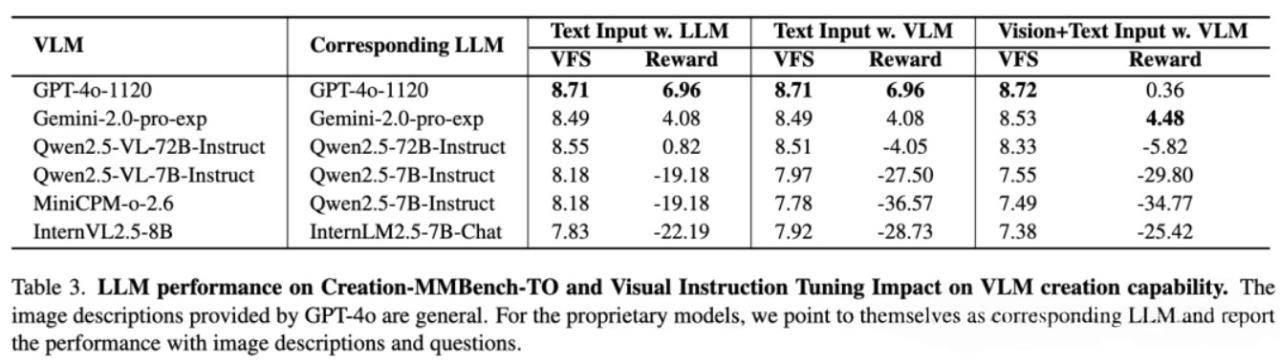
视觉微调的影响
为了进一步了解模型功能,该团队创建了一个纯文本版本,称为创建 - mmbench-to,其中GPT-4O详细描述了图像内容。
仅文本评估显示:
- 封闭式语言模型在创作能力方面的表现略优于开源模型
- GPT-4O在只有文本版本上获得了更高的创意奖励分数,这可能是通过在没有视觉理解约束的情况下将更多地关注发散思维。
- 带有视觉指令微调的开源多模型在创建中持续性能比其基本语言模型更糟糕
这表明视觉指导微调可能会限制模型理解更长的文本和创建扩展内容的能力,从而降低视觉事实分数和创造性的奖励。
现实世界示例:软件工程解释
定性研究揭示了模型如何处理特定专业任务的显着差异:
- qwen2.5-vl由于域知识不足而导致泳道图误认为是数据流程图
- GPT-4O避免了此错误,并提供了更专业的结构化语言,并具有准确的图表解释
这示例亮点在专业任务中,特定于领域知识和详细图像理解的至关重要性,证明了开源和封闭源模型之间的持续差距。

结论
creation-mmbench,带可用的详细信息Girub,在评估多模式大型模型在现实情况下的创造力方面是一个重大进步。有765个实例涵盖51项详细任务和全面的评估标准,它为模型性能提供了前所未有的见解。
基准现在已集成到vlmevalkit,支持一键评估,以全面评估任何模型在创意任务中的表现。这比以往任何时候都更容易确定您的模型是否可以根据视觉输入有效地讲述引人入胜的故事。